Tulisan ini dibuat sebagai catatan (penting), karena berurusan dengan file binary itu seringkali merepotkan dan bikin pusing kepala.
Dataset yang diolah : TRMM 2A25 (Level-2 swath product)/ GPRv7 (by Atsushi Hamada)
Format : Unformatted binary (2 bytes)
Masalah utama yang dihadapi sebenarnya klasik: bagaimana sebenarnya struktur data yang tersimpan dalam data binary unformatted yang nantinya akan diolah dengan Fortran. Tipe data ini sering kali digunakan ilmuwan untuk menyimpan data meteorologi karena lebih mudah dibuat (dibanding HDF atau NetCDF yg butuh library khusus), hemat space di memori/disk, dan tentu saja prosesnya jauh lebih cepat dibandingkan ASCII.
Kesimpulannya, menguasai pengolahan data binary unformatted adalah keharusan bila kita ingin banyak 'bermain' dengan data, secara numerik.
1. Record tersimpan secara serial
Data dalam file terdiri dari record-record. Record ini misalnya bisa berupa curah hujan, atau temperatur. Data curah hujan per-jam selama 1 hari misalnya, terdiri dari 24-record. Untuk data yang lebih kompleks, misalnya 2D atau 3D, jumlah recordnya bisa ratusan atau ribuan.
Yang perlu diperhatikan di sini adalah, mau sebanyak apapun dan bagaimanapun dimensi datanya, entah itu 2D atau 3D, record akan selalu tersimpan secara serial dalam file. Contohnya pada gambar berikut :
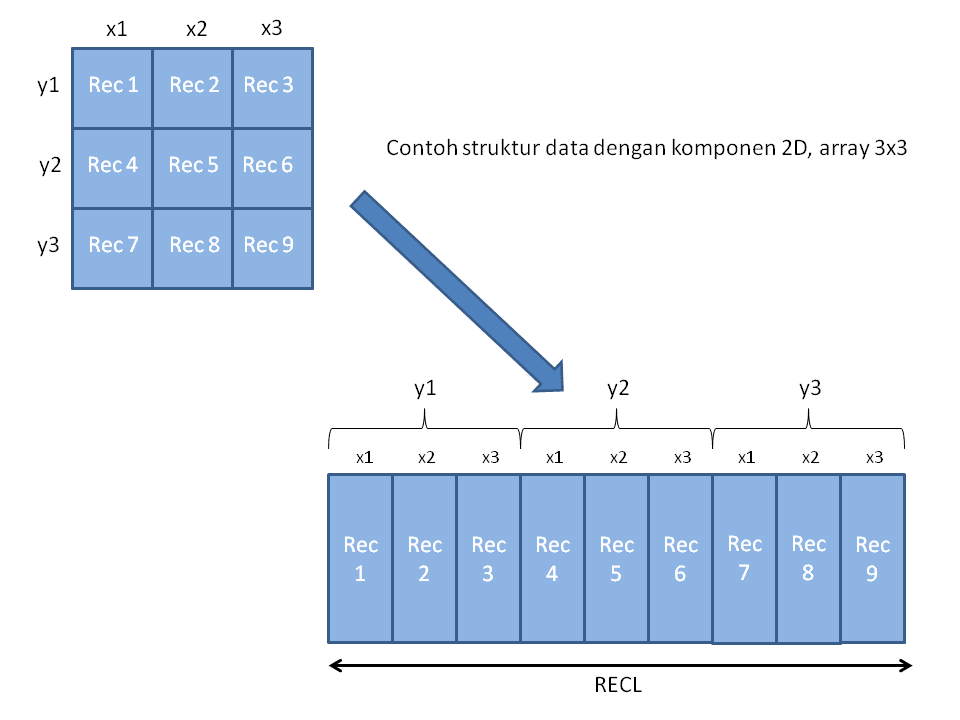
Contoh data array misalnya, data spasial dari satelit. Misalnya record dari data spasial memiliki komponen x dan y, maka record tersebut akan disimpan secara berurut pada data. Dalam hal ini, komputer tidak akan mengerti dimensi atau array, bila kita tidak memberikan instruksi untuk membentuk array dari data yang ada. Dengan kata lain, urutan x dan y dari tiap record tergantung pada kita, atau orang yang membuat/menyimpan data tersebut.
Jadi, bila kita ingin membuka data binary unformatted, kita harus tahu terlebih dahulu dimensi dari data (misal jumlah komponen x, y, z dll). Informasi ini biasanya diberikan oleh penyedia data atau orang yang membuat data tersebut.
Lalu apakah data tersebut bisa dibuka bila kita tidak tahu dimensinya? Jawabnya : Bisa!
Data tetap bisa dibuka (terutama data 1D). Untuk data 2D atau lebih, kita perlu menghitung atau menebak pola arraynya terlebih dahulu (x-nya ada berapa, y-nya ada berapa dst), kalau tidak, kita akan kesulitan mengolah data, walaupun bisa membukanya.
2. Hanya ada satu variabel record (direct access)
Berbeda dengan HDF atau NetCDF yang memiliki metadata yang tergabung dalam 1 file, unformatted binary adalah data yang 'plain', yaitu hanya berisi record tanpa informasi tambahan (metadata atau header). Itu sebabnya, untuk mengolah data unformatted binary dengan GrADS, kita membutuhkan control file (CTL) yang fungsinya untuk memberi informasi ke komputer (GrADS) tentang file yang akan diolah, misal komponen x, y, variabel dll.
Pada data spasial dengan format unformatted binary, record umumnya diakses secara langsung (direct atau random), tidak berurutan, di mana seluruh record akan dimasukkan ke dalam satu variabel/array record. Contoh di Fortran :
read(10,rec=1) ((rain(i,j),i=1,IDIM),j=1,JDIM)
Pada contoh di atas, seluruh record akan dimasukkan ke dalam array 2D dengan nama 'rain' dengan komponen i dan j. Untuk mengakses seluruh record, kita hanya perlu menggunakan record identifier 'rec=1' dan array 'rain', diikuti dengan indeks i dan j.
Intinya, berapapun dan apapun nama variabelnya ketika data dibuat, untuk membacanya, kita hanya perlu menggunakan 1 array dan kita bisa menggunakan nama apapun untuk nama array yang menampung record dari data tersebut.
Contoh: data yang dibuat dengan nama variabel/record 'hujan', bisa dibaca kembali dengan nama variabel lain, misal 'rain'. Kenapa bisa begitu ? Kembali ke atas, karena ini adalah data unformatted alias plain, nama record/variabel bisa dianggap tidak ada.
Bila kita membaca data binary dengan 2 variabel, maka dalam file, kedua variabel tersebut akan memiliki nama record/header yang sama. Keduanya akan dibedakan berdasarkan urutan record dalam data. Misal variabel A memiliki record 1-10, variabel B memiliki record 11-20 dst (perhatikan poin 1 di atas)
3. Record length (direct access)
RECL atau record length ini juga seringkali membingungkan, apalagi sedikit sekali referensi yang membahasnya. Kalaupun ada, biasanya bahasanya sudah 'tinggi' banget, nggak cocok dibaca sama pemula kayak saya. Setelah beberapa kali percobaan, akhirnya saya bisa memahami apa yang dimaksud dengan RECL.
RECL adalah panjang record dari data, dalam byte. Untuk data yang diakses secara langsung (direct/random), RECL ini wajib dicantumkan sebelum mengakses data. Contoh :
open(10,file=fname,
& form='unformatted',access='direct',recl=4*IDIM*JDIM,
& status='old')
& form='unformatted',access='direct',recl=4*IDIM*JDIM,
& status='old')
Nah, bagaimanakah menentukan RECL ini ? Untuk data unformatted yang diakses secara langsung, RECL bisa dihitung dengan mengalikan kapasitas record dengan jumlah recordnya. Misalnya data spasial dengan 3600 komponen x dan 1200 komponen y, disimpan dengan record/variabel bertipe integer 2-byte, maka RECL = 2*3600*1200 = 8640000 bytes = 8.64 MB.
Fun fact : ukuran RECL mencerminkan ukuran dari file data tersebut dan bisa diketahui dengan perintah INQUIRE pada Fortran.
4. Jenis data dan jumlah record dalam byte
Seperti yang dijelaskan di poin 3 di atas, RECL mencerminkan ukuran file, dan ditentukan oleh kapasitas dan jumlah record. Kalau tidak ingin harddisk atau memori komputer cepat penuh, maka anda perlu memperhatikan jenis data dan jumlah record ketika akan menyimpan data.
Tipe data yang digunakan untuk menyimpan angka/bilangan dalam Fortran biasanya adalah integer dan real. Integer digunakan untuk menyimpan bilangan bulat (tanpa koma), dan sering digunakan karena lebih hemat space. Ada dua jenis integer biasa yang digunakan, yaitu 2-byte dan 4-byte integer.
2-byte integer bisa digunakan untuk menyimpan angka -32767 sampai dengan 32767. Perhitungannya sederhana.
Komputer hanya mengenal bilangan biner (0 dan 1), sehingga bilangan apapun akan dikonversi ke bilangan biner untuk bisa diproses komputer. 1 bit (binary digit) bisa digunakan untuk menyimpan 2 bilangan (1 dan 0 saja), 2 bit bisa digunakan untuk menyimpan 4 bilangan (00,01,10,11 atau 0,1,2,3 dalam desimal), dan seterusnya.
Artinya jumlah data bisa ditentukan dengan rumus 2 pangkat jumlah bit. Sehingga, data dengan ukuran 2 byte (16 bit, karena 1 byte=8 bit), bisa digunakan untuk menyimpan 2**16 bilangan = 65536 bilangan. Tapi, karena bit pertama data digunakan untuk menyimpan tanda positif/negatif, maka yang tersisa adalah 2**15 bilangan = 32768, jadi mulai dari -32767 sampai +32767 (+-111111111111111 dalam bilangan biner).
Hal yang sama juga berlaku untuk data integer 4-byte (32-bit). Untuk integer 4-byte jumlah datanya adalah 2**31= 2147483648 bilangan, mulai dari -2147483647 sampai + -2147483647.
5. Urutan record untuk unformatted binary GrADS
Masih ada urutannya dengan poin 1 dan 2 di atas.
Sebenarnya urutan record bisa diatur sesuka hati, tapi untuk unformatted binary GrADS GPRv7, file CTL-nya seperti ini :
dset /home/DATALINK/GPRv7/201301/GPR2013011686417.Lev80.gdat
title PR 2a25 data for GrADS
*options little_endian
options big_endian
undef -9999
xdef 1 linear 180. 0.5
ydef 49 linear 1 1
zdef 80 linear 250. 250.
tdef 9150 linear jan0001 1yr
vars 10
lat1 0 -1,40,2,-1 flat=lat1+lat2*0.001
lat2 0 -1,40,2,-1 flat=lat1+lat2*0.001
lon1 0 -1,40,2,-1 flon=lon1+lon2*0.001
lon2 0 -1,40,2,-1 flon=lon1+lon2*0.001
flag 0 -1,40,2,-1 rainflag 2byte integer
method 0 -1,40,2,-1 methodflag 2byte integr
rain1 80 -1,40,2,-1 rainfall*100 2byte integr
rnsfc 0 -1,40,2,-1 near-sfc rain*100 2byte integr
rave1 0 -1,40,2,-1 rainave(2km-4km)*100 2byte integr
rave2 0 -1,40,2,-1 rainave(top-bottom)*100 2byte integr
endvars
Setelah dibuka dengan Fortran, inilah urutan record pada data unformatted binarynya :
read(10,rec=1)(((datfile(j,varnum,t),j=1,JDIM),varnum=1,VARS)
& ,t=1,TDIM)
Sehingga pola urutan recordnya :
- y adalah dimensi terkecil (karena x=1), dengan 49 komponen.
- variabel adalah dimensi kedua, 89 komponen. Kenapa 89 ? Karena ada satu variabel yang memiliki 80 level vertikal. Sisa variabel yang lain hanya memiliki 1 level (permukaan).
- t adalah dimensi ketiga, dengan 9150 komponen.
- x (atau y, bila x=1)
- variable level (z)
- variable name
- y (atau t, bila x=1)
- t
Hallo mas Bro.... :)
ReplyDeleteitu ko ada nama atshushi hamadanya??
senseinya mas ardhi ya??
klu iya, wah mantabs bgt......aku juga lagi baca2 paper beliau
aku lagi riset pake data Himawari neh... :)
oya, saya kirim email ke yahoo mas ardhi..semoga masih aktif ya...
yoroshiku..
Hallo, wendi-san. Hamada-san itu postdoc di labku :D
Deletewah keren.....mas ardhi..
Deletesaya butuh bgt bantuan beliau..
ntar kenalkan saya dengan dia ya...
yoroshiku ne... :)